넷플릭스, 포스퀘어, 플립보드 등 유명 웹서비스가 일시적으로 서비스 장애를 겪었다. 미국 버지니아주에 위치한 아마존웹서비스(AWS) 애시번 데이터센터에서 장애가 발생한 탓이다.
AWS 측은 "미국 동부 지역에 위치한 데이터센터서 발생한 가용선 존 속도가 저하 문제에 대해 원인을 조사하고 있다"라며 "EBS 볼륨에 장애가 발생하면서 이를 이용하는 다수 웹사이트가 다운됐다"라고 설명했다. 몇시간 뒤 AWS는 "EC2 인스턴스와 EBS 볼륨은 현재 다른 가용선 존에서 정상적으로 작동하고 있다"라며 "노스 버지니아 지역 문제도 곧 해결돼 정상적인 서비스가 가능할 것으로 보인다"라고 해명에 나섰다.
AWS 웹사이트를 살펴보면 이번 사고는 US-east-1 지역의 단일 가용성 존에서 시작한 EBS 볼륨 성능 장애서 비롯됐다. EBS 기반 인스턴스에 장애가 발생하면서 동시에 로드 밸런스인 ELB에도 영향을 끼쳤고, 이 과정에서 AWS EC2가 불안해지면서 AWS를 이용하는 웹서비스 사이트들이 장애를 경험했다.
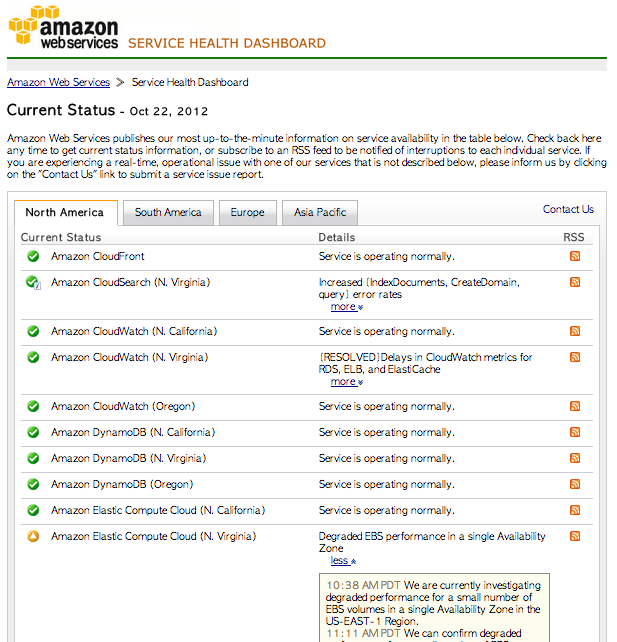
애시번 데이터센터는 올해 들어 벌써 4번이나 문제를 일으켰다. 지난 4월과 6월에 발생한 데이터센터 장애는 허리케인 같은 자연재해로 인한 정전이었기에 '어쩔 수 없었다'는 핑계라도 댈 수 있었다. 이번엔 둘러댈 핑계도 없다. 애시번 데이터센터는 엘라스틱 블록 스토리지(EBS) 서비스가 다운되면서 문제를 일으켰다.
여기에 아직까지 서비스 장애 원인도 명확히 밝혀지지 않고 있어, 애시번 데이터센터 클라우드 안정성 문제가 다시 도마위에 올랐다. 애시번 데이터센터는 현재 AWS 사용 고객의 70%가 몰려 있는 데이터센터다. 그만큼 장애가 발생하면 피해를 입는 고객도 많다. AWS 장애 소식을 처음 전한 더넥스트웹을 비롯해 외신들은 "AWS 애시번 데이터센터에서 또 다시 장애가 발생했다"라며 "애시번 데이터센터 가용성 수준이 의심된다"라고 전했다.
그동안 AWS는 장애가 발생할 때마다 애시번 데이터센터는 가용선존을 통해 자연재해로 인해 데이터센터 문제 발생시 자동으로 백업 인프라를 가동하는 리던던시 수준이 높기 때문에, 리던던시 서비스를 사용하는 기업들은 별 장애 없이 클라우드 서비스를 누릴 수 있다고 설명했다.
리던던시는 한쪽 데이터센터에 장애가 발생하면 다른 곳에 위치한 데이터센터에서 해당 서비스를 이어 작업하는 일종의 백업 서비스다. AWS 리던던시 서비스를 도입한 기업이라면 애시번 데이터센터가 멈춰도 서비스가 중단되지 않아야 한다. 그런데도 인스타그램, 핀터레스트, 넷플릭스 등의 사이트는 멈췄다. 이들 업체들이 비용 절약을 위해 리던던시 서비스를 도입하지 않는 등 백업 문제에 소홀했던 것일까.
소프트웨어 컨설팅과 개발 전문가들이 모여 있는 이노디에스는 생각을 좀 달리 했다. 이들은 자사 블로그를 통해 "백업 문제로 클라우드 문제가 모두 해결되는 게 아니다"라며 "단순히 비용 문제로 서비스 분산이 이뤄지지 않아 이들 서비스가 장애를 겪다고 바라보는 건, 문제를 너무 쉽게 생각하는 게 아니냐"라고 설명했다.
예를 들어 설명을 위해 데이터베이스는 사용하지 않고 파일 시스템만 사용해 단순하게 정적인 페이지만 서비스하는 A라는 회사가 있다고 가정합시다. A사는 AWS EC2 인스턴스를 us-east-1에 하나 생성했는데, 공교롭게도 이번 시스템 장애로 인해 특정 시간 동안 서비스가 불가능해져버렸습니다. 다음에 동일한 장애가 일어나지 않도록 하려면 어떻게 해야 할까요? 가장 간단한 방법으로 us-east-2에 AWS EC2 인스턴스를 하나 더 만들고 ELB를 걸어 양쪽으로 서비스 부하를 분산시키면 됩니다. 정적인 서비스이므로 두 서버 모두 stateless하기에 로드 밸런서를 거쳐 어느 쪽으로든 서비스를 요청할 수 있고 동일한 응답을 받게 됩니다.자 그렇다면 us-east 전체에 장애가 생긴다면 어떤 일이 벌어질까요? us-east-1과 us-east-2 모두 접속이 불가능해지며 ELB도 제구실을 못하므로 역시 서비스가 불가능해집니다. 이를 회피하려면 ap-northeast-1과 ap-northeast-2에 AWS EC2 인스턴스를 각각 배치하고 DNS 라운드 로빈 등을 사용해 번갈아가며 서비스에 접속하도록 유도하면 됩니다. 여기까지 설명을 들으면 역시 장애 회피는 비용 문제라는 생각이 들 것입니다. 그런데, 서비스 대상 페이지를 저장하는 파일 시스템이 이런 손쉬운 해결책을 어지럽힙니다. 클라우드 특성상 고가의 단일 스토리지를 유지하지 못하므로, ELB의 경우 가용성 존을 넘어가지 못하므로 us-east-1, us-east-2에 각각 파일 시스템을 유지해야 하며, region 자체가 바뀌는 ap-northeast-1과 ap-northeast-2는 두 말할 나위도 없습니다. 파일 시스템 갱신 작업이 일어나지 않는다면 한번만 파일 시스템을 복제해주면 끝나지만 파일 시스템 갱신 작업이 일어난다면 파일 시스템 네 벌에 대한 동기화 문제가 발생합니다. 하지만 이런 동기화 작업을 위한 자동화된 서비스는 AWS EC2에서 제공하지 않습니다. 비즈니스 로직도 다르고 파일 시스템 크기도 다르고 CRUD 특성도 다르기 때문에 실제 서비스 회사에서 자신의 서비스 맥락에 맞춰 독자적으로 해결해야 합니다. 이는 아키텍트, 개발자, 운영자를 필요로 하기 때문에 단순히 서비스 비용을 넘어서 추가적인 개발/운영/유지 보수 비용의 투입을 초래하며, 작은 스타트업으로서는 배포/운영 비용 측면에서 클라우드를 사용해 얻는 비용적인 이익을 초과하는 오버헤드가 되기 쉽습니다.
구글이나 페이스북과 다르게 AWS는 지금까지 자사 데이터센터 내부를 단 한번도 공개하지 않았다. 지난 6월에 애시번 데이터센터에서 발생한 장애만 해도 애시번에 데이터센터를 두고 호스팅 서비스를 하는 조이넷이라는 곳에서는 아무런 장애도 발생하지 않았다고 한다. AWS는 구글과 함께 클라우드 인프라 서비스(IaaS) 양대산맥으로 꼽히고 있다. 고객 신뢰 확보를 위해서라도 뭔가 신뢰가 갈 만한 보완책이 필요한 시점이다.
