펌글한 네이버 블로그가 원본보다 검색 결과 상단에 보인다는 지적은 국내 1위 검색 서비스이자, 포털 서비스인 '네이버'를 끊임없이 따라다닌다. 네이버는 이 오명을 벗기 위한 노력을 공개했다.
네이버를 서비스하는 NHN은 10월30일 서울 조선호텔에서 기자간담회를 열고 원본 문서와 유사 문서를 파악하는 '프로젝트 바이오'와 '블로그 검색 반영 센터', 검색 통계 서비스인 '네이버 트렌드'를 발표했다.
원본문서 먼저 찾는 '프로젝트 BiO' 공개
'네이버에서 검색하면 왜 내 기사를 펌한 네이버 블로그가 제일 먼저 보이나요?' 이 질문에 대한 답은 간단하다. 원본 문서를 네이버가 파악하지 못했거나, 파악해도 검색 알고리즘에 제대로 반영하지 않았기 때문이다. 네이버는 1990년대 중반 검색 서비스를 시작하고, 줄곧 이 문제를 풀고자 노력했다고 말했다. 2006년부터는 '프로젝트 BiO(Better is Original)'란 이름으로 해법을 본격 연구했다.
김광현 네이버 검색연구실 공학박사는 "프로젝트 BiO의 핵심은 BiO 시스템으로, 네이버가 수집해 보유한 문서를 대상으로 유사도를 비교해 각 문서의 오리지널리티를 계산해 검색해 반영하는 시스템"이라며 "카페나 블로그에서 어떻게 하면 창작 문서나 저작자의 권리를 보호할 수 있는지를 고민한다"라고 말했다.
"2006년부터 여러 기술을 개발하고 노력하는 과정에서 특허도 보유했습니다. 유사 문서 판독은 2006년부터 시작한 것만은 아닙니다. 검색 서비스를 처음 시작할 때, 웹문서를 수집해 웹 검색을 처음 시작할 때부터 중복 문서 제거는 필수 작업이었습니다. 1990년대 중반, 검색 서비스를 시작할 무렵부터 유사 문서에 대한 고민을 지속해 왔습니다."

▲BiO 시스템은 원본 문서에서 이미지 포함 총 4개의 '청크'를 추려내, 다른 문서와 비교한다. 이때, 생성 시기도 파악한다.

▲위 수식으로 점수를 매겨 원본인지 파악하고 검색 결과에 반영한다.
프로젝트 BiO는 2006년부터 본격 가동하기 시작했다. BiO 시스템이 원본과 베낀 문서를 구분하는 기준은 '청크'다. 청크는 두 문서가 얼마나 비슷한지를 비교하는 기본 단위로, 문서의 구나 절, 문장을 1개의 청크로 나눈다. 이미지는 1장당 1개의 청크가 된다. 바이오 시스템은 A라는 원본 문서에서 파악한 청크를 기준으로 B, C, D 문서는 이 청크를 얼마나 중복해 사용했고 각색했는지를 파악한다.
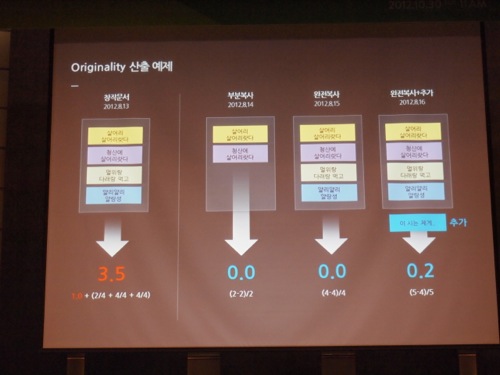
▲모든 문서는 기본 점수 1을 받고 원본인지에 따라, 얼마나 베꼈는지, 독자적인 글은 얼마나 들어갔는지, 얼마나 많이 베꼈는지에 따라 감점 혹은 가산점을 받는다.

▲원본 문서와 유사 문서를 파악하는 기본 단위 '청크'.
일단, 네이버는 문서마다 기본 점수 1점을 매긴다. 원본과 청크가 100% 겹치는 문서는 0점이 되고, 얼마나 각색했는지, 자기 생각을 입혔는지에 따라 점수는 덜 깎인다. 그렇다고 원본 문서가 받는 1점이 최대 점수는 아니다. 원본 문서는 다른 문서가 얼마나 많이 베꼈는지에 따라 가산점을 받는다. 김광현 박사는 "바이오 시스템을 (검색 알고리즘에)적용하면 유사문서는 제거되고 각각의 창작 문서가 상위에 노출된다"라고 설명했다.
그렇다면 '무엇을 원본으로 삼는가'라는 의문이 든다. 청크로 문서가 서로 얼마나 비슷한지 파악하려면, 기준이 되는 원본 문서가 있어야 할 터다. 네이버는 청크로 유사도를 파악하고, 문서 생성 일자도 고려한다고 밝혔다. 위에서 설명한 대로 다른 문서에서 얼마나 많이 인용됐는지도 원본을 파악하는 또 다른 방법이다.
즉, 네이버는 문서 생성 시기와 다른 문서가 얼마나 많이 베꼈는지를 파악해 원본 문서를 고르고, 원본 문서와 청크가 얼마나 많이 겹치는가를 기준으로 유사 문서인지를 판단한다. 이 외에도 원본을 솎아내려고 만든 기준은 다양하지만, 기자간담회에서는 그 중 3개만 공개했다고 네이버는 밝혔다.

▲프로젝트 바이오 진행과정
뉴스 찾는 이용자에겐 '뉴스' 컬렉션을 상위에 노출
다시 처음으로 돌아가, '네이버에서 검색하면 왜 내 기사를 펌한 네이버 블로그가 제일 먼저 보이나요'란 질문을 보자. 이에 대한 세 번째 답은 '네이버가 블로그를 뉴스보다 검색 결과 상단에 보이기 때문'이다. 이 말은 네이버가 이용자의 검색 질의어가 뉴스를 찾는 것인지 블로그 글을 찾으려는지 제대로 파악하지 못했단 뜻도 된다.
김광현 박사는 "이런 문제가 발생하는 가장 큰 문제는 네이버 검색의 특징인 컬렉션 랭킹 때문"이라며 "새 시스템이 적용되면 이용자의 검색 의도가 뉴스를 찾는 것이 분명한 경우 다른 콜렉션에 앞서 뉴스를 통합검색 상단에 노출한다"라고 밝혔다.
10월30일 오후 2시부터 네이버는 이용자가 뉴스를 검색하려는 것인지, 검색 의도를 파악해 뉴스 검색 결과를 상단에 보일지를 결정한다. 네이버는 사용자 질의어와 기사의 적합도, 질의 의도, 사용자 선호도 등 3가지 요소로 이용자가 뉴스를 검색하려는 건지 파악한다. 이렇게 따졌을 때 이용자가 뉴스를 찾으려는 게 분명하다고 판단하면, 통합검색 결과에서 뉴스 분야 검색 결과를 상단으로 올린다.

▲사용자가 네이버에서 뉴스를 검색하려는지 파악하는 데 사용되는 알고리즘. 위 수식은 사용자 질의와 기사의 적합도, 질의의도, 사용자 선호도를 반영한다는 걸 나타낸다.
이와 함께 네이버는 '블로그 검색 반영 센터'를 마련해 ▲내 블로그 글을 검색에 반영해달라거나 ▲원본으로 반영해달라는 요청을 받고 ▲무단 복사글도 제보받을 계획이다.
그리고 네이버 검색 현황을 보이는 검색 통계 서비스 '네이버 트렌드'도 공개했다. http://trend.naver.com으로 접속하면, 특정 키워드에 대한 검색횟수 추이를 2007년부터 주간 단위로 살필 수 있다.
네이버 트렌드는 최대 5개 키워드를 그래프로 비교해 보여주며, 검색횟수는 실제 수치 대신 최댓값을 100을 기준으로 삼아 보여준다. 검색횟수가 가장 많은 때를 100으로 잡고 7번째까지를 추려, 당시 해당 키워드와 관련한 뉴스를 같이 보일 계획이다. 뉴스를 노출하는 기준은 클릭 수 50회가 넘는 네이버 뉴스인지에 따라 클릭 수순으로 보여준다. 검색·비교 결과 그래프는 파일로 내려받을 수 있다.
네이버 트렌드는 10월30일부터 서비스를 시작한다.
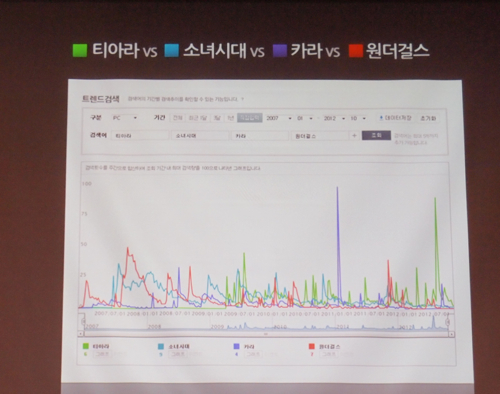
▲걸그룹으로 본 네이버 트렌드. 네이버 쪽은 검색량 자체가 그 사람에 대한 인기를 의미하는 것은 아니라고 말했다.
아래는 기자간담회에서 네이버쪽과 기자들 사이에 오간 문답이다.
- 지난 9월 기자간담회에서 KISO에 검색어 서비스 검증받겠다고 했다. 진행 상황이 궁금하다. 그리고 둘 이상의 창작자가 서로 원본 문서 소유자라고 주장할 때는 어떻게 대응하나.= (한종호 이사) KISO에는 중요한 정책과 심의 결정하는 정책위원회가 있다. 여기에는 외부 전문가 5명과 회원사에서 1명씩 나와 총 9명으로 구성되는데, 검색 서비스 검증 위원회는 외부 위원 5명으로만 구성된다. 현재 김기중 변호사가 위원장으로, 소위원회를 구성해 1차와 2차 검증 회의를 진행했다.
(김유원 박사) 하나의 문서에 대해서 원본임을 주장하는 측이 둘 이상이라는 갈등 요소가 생겼을 때, (네이버가) 직접 판단하기 어렵다. 중재를 시도하겠지만, 갈등이 해결되지 않는다면 외부와 소통하며 합리적인 방안을 찾겠다.
- 이 시스템이 적용되면 펌질 블로거는 트래픽이 줄 것 같다. 그리고 (오늘 발표에서)외부에 있는 원본 콘텐츠를 강화하려는 노력은 빠진 것 같다.
= (이윤식 검색본부장) 펌질에 따른 트래픽 감소 부분은 네이버에서 매우 곤혹스러운 부분 중 하나다. 다른 검색 사업자도 마찬가지겠지만, 우리가 검색을 변경하면 트래픽에 변화가 생길 수밖에 없는 것 같다. 원본이 우선이어야 한다는 공감대가 창작자와 사용자 사이에 형성됐다고 본다. 네이버는 창작자만을 대상으로 할 수 없기 때문에 많은 고민을 하고 있다. 지금부터 더 나은 서비스를 하며, 이해관계가 걸린 많은 분과 공감대를 형성하기 위해 노력하겠다.
네이버 내부에서도 검색과 타 서비스 관계는 입장이 다르다. 검색은 내부와 외부의 모든 콘텐츠를 같은 기준으로 판단해야 하기 때문에 랭킹을 정할 땐 내·외부 차이를 두지 않는다. 내부 콘텐츠가 더 우대받는 현상이 생긴다면 내부 콘텐츠와 외부 콘텐츠에 차이를 둬서는 아니고, 콘텐츠 자체가 어느 쪽이 원본에 가까우냐에 따를 것이다. 외부 콘텐츠에 원본이 더 많다면 외부 콘텐츠로 트래픽이 늘어날 거다.
- 소비자 처지에서 원본이 반드시 자신이 찾던 정보라고 볼 순 없다.
= (김광현 박사) 누가 봐도 명백하게 복사한 문서는 제거돼도 괜찮겠지만, '약간 변형한 문서는 어떻게 할까'를 두고 알고리즘을 개발하는 사람으로서 곤혹스러웠다. 오리지널리티 점수란 게 있는데, 약간 개량된 문서는 무조건 제거하기보다는 랭킹을 조절하고자 한다. 원본 문서가 나오고 개량된 문서는 그보다 하단에 노출하는 걸 목표로 개발하고 있다.
- 네이버 검색에서 해외 문서는 부족한 편이다.
= (김광현 박사) 네이버는 기본적으로 한글 문서를 서비스한다. 그렇다고 해외 문서를 전혀 고려하지 않는 건 아니다. 해외 문서 중 중요하다고 판단하는 문서나 사용자가 많이 방문하는 건 수집해서 서비스에 노출한다.
- 네이버 트렌드는 실시간급상승검색어와 같이 검색을 유도한 방법으로 발생한 검색횟수도 포함하는가.
= (김유원 박사) 특별히 트래픽 종류를 구별하지 않는다. 네이버 추천으로 발생한 검색도 사용자가 손으로 입력한 검색과 똑같이 간주한다. 네이버 트렌드를 만들 때는 웹이란 생태계에서 네이버도 플레이어, 외부 SNS로 소식이 퍼지는 것도 하나의 구성원이라고 생각해, 모든 검색 행위를 똑같은 것으로 간주한다.
- 블로그 검색 반영 센터는 소위 '봇'으로 블로그 글을 검색 상단에 올리려는 행위에 대한 것도 다룰 예정인가.
= (김광현 박사) 그 문제는 다른 방법으로 개선하려고 한다. 홍보성 글을 개선하는 작업은 지금도 꾸준하게 하고, 다른 프로젝트로 진행하고 있다. 홍보성 글와 블로그 검색 반영 센터가 다룰 내용은 다르다.
- 미국은 대선 후보인 오바마와 롬니 지지율을 구글 트렌드로 파악한다. 네이버 트렌드를 선거에 어떻게 활용할지 궁금하다.
= (김유원 박사) 법적인 검토를 완전하게 끝내지 않았지만, 대통령 후보자 이름을 특별하게 제한할 생각은 없다. 네이버가 검색 횟수를 제공하지만, 해석과 판단, 투자는 여러분의 몫이다.