지난 5월27일 <오마이뉴스>는 카카오가 카카오톡의 웹주소를 다음 웹검색에 반영하는 듯하다는 취지의 기사를 냈습니다. 내부용으로 확인을 위해 만들어 둔 문서를 채팅방에 공유했는데, 그게 약 1시간 뒤에 다음 웹검색에 잡혔다는 겁니다.
여기에 트위터 @pigori 님의 트윗도 3천번 이상 리트윗되며 카카오에 대한 분노를 불러왔습니다. 그간 원드라이브 웹주소를 카톡에서 지인들에게 알려주는 식으로 공유했는데, 카카오톡 링크가 다음 웹검색에 노출되는 바람에 개인적인 사진들이 공개됐다는 겁니다. 이 사례는 ‘카카오가 다음 웹검색에 반영한 웹주소에 일반적으로 공개된 웹주소뿐만 아니라 웹주소를 가지고 있는 사람만 접근할 수 있는 비공개 웹주소까지 모두 반영시켜버린 게 아니냐’는 의혹을 키웠습니다. 비공개 웹주소가 검색에 반영되면 문제는 상당히 커집니다. 지인과만 보려고 했던 드라이브 링크, 유튜브 비공개 영상 등이 만천하에 공개되는 셈이 됩니다. 생각만 해도 아찔하죠.
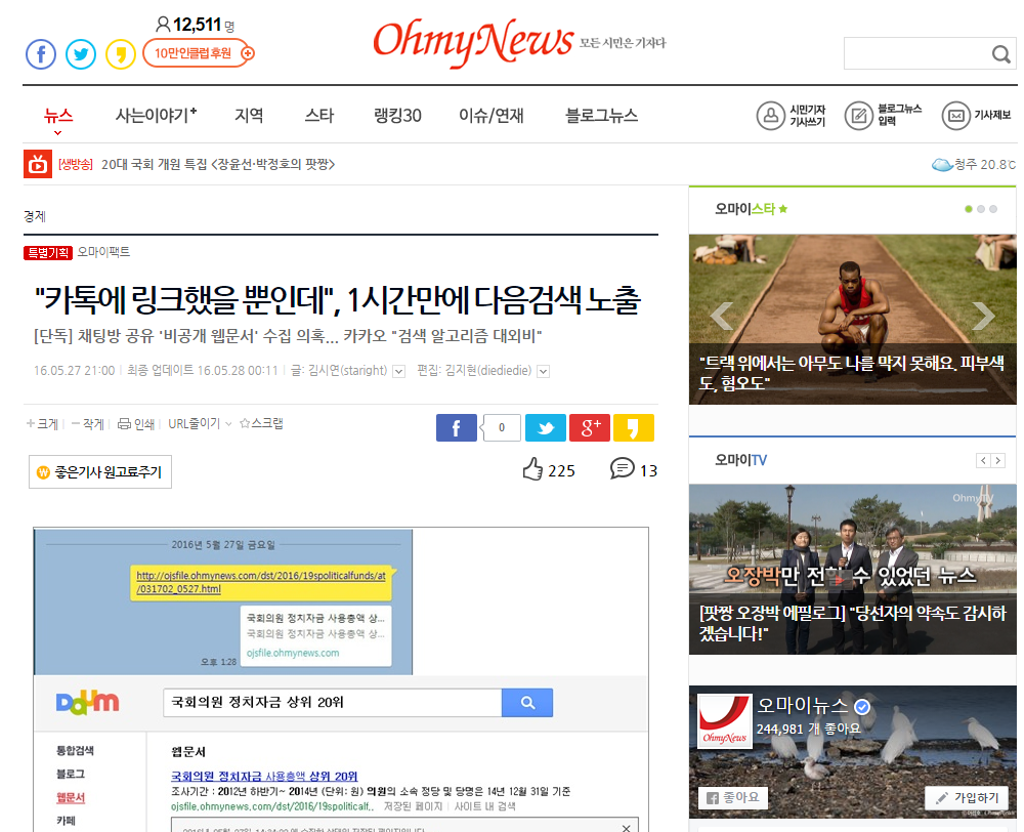
검색 연동을 중지한 상황에서 확실하게 확인하기는 어려웠습니다. 저 또한 지난 기사에서 원드라이브와 <오마이뉴스>의 사례를 바탕으로 비공개 웹주소 또한 반영한 것으로 판단했습니다. 카카오는 이에 대해 "우리가 무척 잘못한 건 맞지만, 절대 비공개 링크는 다음 웹검색에 반영하진 않았다"고 추가로 해명했습니다.
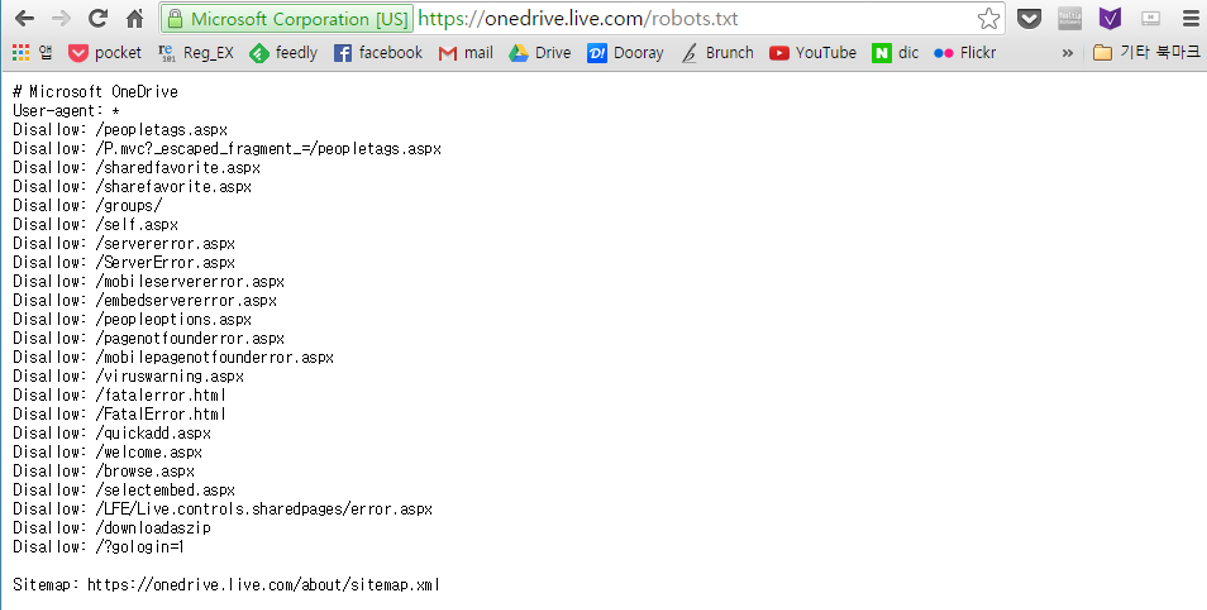
공개 웹주소를 판단하는 근거는 ‘robots.txt’
결론부터 이야기하면 카카오는 ‘공개된 URL’만 다음 웹검색에 반영했다는 주장은 맞는 것으로 보입니다. 카카오가 공개 웹주소인지의 아닌지를 판단하는 기준은 'robots.txt'입니다. 기본적으로 검색엔진은 웹문서를 검색 결과에 반영하기 위해서 웹문서를 수집하고 다닙니다. 이 과정에서 검색엔진에 걸리고 싶지 않은 문서는 robots.txt 파일에 ‘가져가지 마라(Disallow)’라고 적어둡니다. 그러면 웹을 돌아다니는 로봇이 ‘그래 이건 안 가져갈게’라고 판단해 안 가져갑니다. 딱히 말이 없으면 가져가고요.
robots.txt는 권고 사항입니다. ‘써 놓으면 가져가지 마라’는 느슨한 약속인 셈입니다. 약속을 무시하고 가져가려면 가져갈 수는 있습니다. 사용자들은 카카오가 그걸 무시하고 가져간 건 아니냐는 의심을 하게 됐습니다. 원드라이브의 사례가 이를 뒷받침했습니다.
사적 자료, URL 공유 주의해야
[academy]그러나 원드라이브는 원래 검색에 걸립니다. 원드라이브의 공개 설정에 보면 로봇의 크롤링을 허용하고 있습니다. 구글 드라이브도 마찬가지입니다. 그러나 구글 드라이브의 경우 링크로 공개할 때 공개 범위를 설정할 수 있습니다. 구글코리아 측은 “구글 드라이브의 문서는 공유 설정을 ‘사용→모든 웹 사용자’로 설정하는 경우에만 검색 대상에 포함된다”라고 설명했습니다.
원드라이브의 링크는 검색을 막아 두지 않았습니다. 검색에 잡히는 게 껄끄러우면 링크 공유가 아니라 e메일 주소를 기반으로 초대해야 합니다. 원드라이브를 서비스하는 마이크로소프트 측은 “원드라이브의 링크는 공유를 위해 생성되며 해당 문제는 링크가 유통되는 채널의 정책이므로 이쪽에서는 확인해드릴 사항이 없다”라고 공식 입장을 밝혔습니다. 카카오톡이 아니더라도 민감한 문서라면 원드라이브에서 링크로 공유하면 안 됐던 겁니다. <오마이뉴스>의 경우도 마찬가지입니다. 로봇으로 막아두진 않았기 때문에 기술적으로는 웹에 누구나 접근할 수 있게 공개된 문서라고 보는 게 맞습니다.

공개된 URL도 검색 품질 따져 노출해야
‘어차피 공개된 URL이기 때문에 카카오톡에서 가져온 웹주소를 반영하는 게 딱히 잘못은 아니지 않나’라고 보는 입장도 있습니다. 어차피 카카오톡에서 가져왔어도 보였을 거란 이야깁니다. 카카오 측도 최초 트윗에서는 ‘공개된 URL’이라는 점을 강조했으나, 이후 사과문에서는 해당 행위가 어떤 맥락에서 실수였는지를 이야기합니다. 이 대목에서는 어제(6월2일) 카카오가 내놓은 해명 일부를 보겠습니다.
카카오톡은 URL 미리보기 기능을 제공하기 위해 스크랩 서버를 활용했고, 다음 웹검색은 검색 결과의 품질을 높이기 위해 스크랩 서버의 URL을 사용했습니다. 카카오톡과 검색을 직접 연동하지 않았고, 개인 정보 없이 URL 만을 이용했으며, 로봇 규약을 준수하면서 검색이 허용된 문서를 수집했기 때문에 문제가 없을 것이라고 판단했습니다. 그러나, 검색을 목적으로 추출한 정보가 아니기 때문에 공개를 의도하지 않은 웹문서의 URL이 포함될 가능성을 깊이 생각하지 못했습니다. 잘못 내린 결정이었고 많이 부족했습니다. 저희의 잘못을 인지한 즉시 스크랩 서버의 검색 연동을 중단하였으며, URL은 모두 검색에서 제외, 삭제했습니다.
일반적으로 사용자가 대화 하다가 건네는 링크는 지인과의 대화의 맥락 속에서 등장합니다. @pigori님의 원드라이브의 사례가 대표적입니다. 친구들과 다녀온 MT 사진을 공유하기 위해 카카오톡으로 웹주소를 던져줬습니다. 이처럼 카카오톡의 활용은 대개 지극히 사적인 경우가 많습니다. 대화방에서 공유되는 링크는 친구의 소소한 사생활 이야기가 담긴 블로그 글일 수도 있습니다. 기술적으로는 ‘공개된 URL’이지만, 사용자의 인식 상에서는 그렇지 않은 셈입니다.
크롤러가 웹에서 웹문서를 수집하는 데는 일정시 간이 소요됩니다. 그러나 카카오톡을 통해 공유된 웹주소가 다음 검색으로 반영이 되기까지는 오랜 시간이 걸리지 않습니다. 카카오는 “구글, 네이버, 다음에서 일반적으로 크롤러가 웹주소를 반영해 수집한 것보다는 빠르게 반영됐다”라고 말했습니다.
[rel]카카오톡에 올라오는 웹주소의 성격을 생각하면, 이게 기술적으로 공개된 URL이라고 한들 굳이 다음 웹검색의 품질 향상에 반영할 이유가 없습니다. ‘공개되긴 했지만, 사적일 수 있는’ 웹문서를 웹 검색에 더 빠르게 반영할 이유도 없죠. 사람들이 일반적으로 궁금한 정보를 찾기 위해 존재하는 검색 서비스에, 사적인 내용이 많이 담겨 있을 웹주소는 그리 적절한 검색결과도 아닙니다.
대다수 사람은 ‘공개된 URL’이 무엇을 의미하는지, ‘robots.txt 파일로 검색엔진의 크롤링을 막는다는 게’ 무엇인지 인지하고 있지 않습니다. 웹문서를 작성하고 활용할때도 ‘기술적 공개 여부’로 웹문서에 담는 내용을 결정하진 않습니다.
일반적인 사용자의 사용 패턴을 고려하면 기술적으로 공개된 URL이라고 해도 그걸 가져다 웹검색 품질 향상에 써서는 안 됐던 겁니다. 또한 약관상에도 사용자가 대화방에 올린 웹주소를 서비스 품질 향상에 사용할 수 있는 이유가 되는 명확한 근거가 없습니다. 카카오는 “이용자의 동의 없이 다음 검색에 노출한 점에 대해 사과한다”라고 입장을 밝혔습니다.
이용자 입장과 감정 고려해야
카카오가 어떤 악의적인 의도를 가졌기에 이런 사태가 벌어졌다고 보진 않습니다. 아마 검색 품질 향상도 궁극적으로는 사용자에게 더 좋은 검색 결과를 주고자 했기 때문일 겁니다. 서비스 제공자가 온전히 사용자의 입장이 되긴 어렵습니다. 만드는 사람이 온전히 쓰는 사람의 입장이 되긴 어렵겠죠. 그럼에도 수많은 사용자가 활발하게 이용하는 서비스라면 사용자의 입장과 감정을 이해하기 위해 최선을 다해야 합니다. 이번 카카오톡 웹주소 검색반영 사태가 아쉬운 이유입니다.