포털 검색은 현대인의 일상이다. 매일 아침 ’핫‘ 이슈를 실시간 급상승 검색어를 통해 확인한다. 어떤 인물이 혹은 어떤 이슈가 대한민국의 관심을 주도하고 있는지 검색을 통해 발견하고 확인한다.
무심코 검색어를 클릭하거나 키워드를 입력하면 수많은 검색 결과가 일목요연하게 정리돼 나타난다. 관련 콘텐츠가 어림잡아 수만, 수십만 건이 될 텐데도, 검색 결과는 알토란 같은 정보만 뽑아서 보여준다. ’필터링’의 힘이다.
우리가 매일매일 포털 모바일앱에서 만나는 검색 결과물들은 알고리즘의 계산 결과다. ‘지하철 파업’이 이슈라고 한다면 검색엔진은 지하철 파업과 관련된 문서 가운데 현재 가장 관련성이 높은 것들만 골라서 차려준다. 누가 봐도 고개를 끄덕일 정도의 정확성과 적절한 공간 배열에 깜짝 놀랄 때도 있다.
'TF-IDF'라는 알고리즘은 검색 키워드에 가장 부합하는 문서를 검색 결과 최상위에 배치하는 알고리즘 가운데 하나다. 키워드 검색을 기반으로 하는 검색엔진이라면 이 알고리즘을 피해가긴 어렵다. 문서를 중요도에 따라 줄세우는 데 기반이 되는 알고리즘이기 때문이다.
TF-IDF의 개념과 역사

TF-IDF 가중치 알고리즘은 'Term Frequency'와 'Inverse Document Frequency'가 결합된 알고리즘 명이다. 각 단어의 첫 자를 빼어내 알고리즘 이름으로 붙였다. 해석하면 ‘단어 빈도–역문서 빈도‘쯤 된다.
TF-IDF는 문장에 사용된 모든 단어에 점수를 부여하는 알고리즘이다. 때문에 가중치라는 표현이 반드시 따라붙는다. 단어의 경중을 통계적으로 가려내 중요한 키워드를 감별해낸다. 그 결과를 바탕으로 문서 내 비중있는 단어 또는 단어 묶음을 추출하게 된다.
TF는 정보 검색의 대가인 한스 피터 룬(Luhn, H. P., 1957)의 이론에 빚지고 있다. 룬은 1950년대 정보 검색 프로세스와 자동 초록 작성 방법에 대해 깊은 관심을 두고 있었다. 늘어나는 문서를 일일이 코딩하지 않고 기계로 대체할 수 있는 방법을 찾는 중이었다. 그러다 그는 한 가지 중요한 전제를 발견하게 된다. 중요한 단어나 아이디어는 특정 문서에 등장하는 빈도가 높더라는 것이다.
처음엔 문서를 인덱싱하는 작업에 이 명제를 적용했다. 결과치가 나쁘지 않았던지 그는 이후 자동 초록 작성(abstracting) 기술에도 이 알고리즘을 적용했다. 빈발하는 단어에 우선 순위를 적용함으로써 정보 검색의 효율을 높이고 초록 작성에도 도움을 얻기 위한 목적이었다. 그의 아이디어는 곧 IDF와 만나면서 완성체가 됐다.
TF-IDF의 작동 원리와 전제 조건들
TF-IDF는 ’특정 단어의 중요도는 단어가 출현한 횟수에 비례하고 그 단어가 언급된 모든 문서의 총수에 빈비례한다‘는 명제에 기초하고 있다(이말례·배환국, 2002). 수식으로 표현하면 다음과 같다.
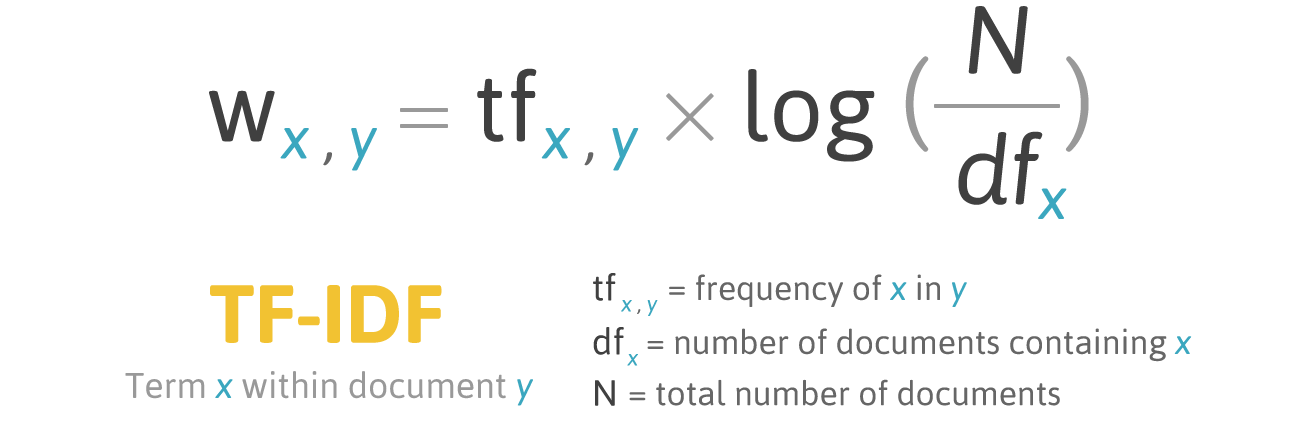
예를 들어 4건의 정치 기사가 현재 중요하게 다루는 소재가 무엇인지 확인하라는 과제를 받았다고 하자. 현재 정치 뉴스 검색 결과에 5건의 기사(문서)가 저장돼 있다. y1은 정당 기사, y2는 청와대발 기사, y3는 총리실발, y4는 통일외교 기사다. 이 4건의 문서에서 이정현은 4회, 국회의원 6회, 대통령 9회 등장했다. 빈도수로만 판단하면 대통령이 가장 중요한 소재가 된다.
이들 뉴스가 비중있게 다루는 단어가 무엇인지 TF-IDF로 계산해보면, 가장 빈도수가 높았던 단어 ’대통령‘이 가장 낮은 중요도로 집계된다. 반면 ’이정현‘이라는 단어는 TF-IDF 값이 16으로 세 단어가 가운데 가장 높은 수치를 나타내게 된다. 빈도수는 낮았지만 비중은 가장 높은 단어가 되는 것이다. 여러 문서에서 자주 등장하는 단어는 중요하지 않을 확률이 높다는 가정을 충실히 반영하고 있다.

TF-IDF는 수식으로만 보면 간단해 보인다. 하지만 정확한 가중치를 계산하기 위해서는 여러 변형 절차를 거쳐야 하는 것이 일반적이다. 특히 문서 길이에 따라 가중치를 달리 적용해야 하는 문제부터 해결할 필요가 있다.
A와 B라는 문서에서 ’블로터‘라는 키워드가 각각 10번과 15번 등장했다고 하자. B문서는 A문서보다 1.5배나 더 길다. 문서가 길어지면 자연스럽게 특정 단어가 출현할 빈도가 높아지기 마련이다. 단어 출현 빈도(TF)라는 측면에서 블로터라는 단어가 어느 문서에서 더 비중있게 다뤄지고 있을까.
이를 측정하기 위해서는 정규화(normalization)라는 과정이 진행돼야 한다. 이를테면, A라는 문서가 총 150개 단어로, B 문서는 250개 단어로 이뤄졌다고 하면, '블로터'의 TF를 정규화한 값은 A에선 10/150=0.066, B에선 15/250=0.6이 된다. 블로터라는 단어가 B 문서보다 A에서 상대적으로 더 자주 등장한 셈이 된다.
복잡성은 TF의 정규화에만 그치지 않는다. 불용어 처리 문제도 항상 염두에 둬야 한다. 이 과정에서 알고리즘 설계자의 의도가 깊숙이 개입될 수 있다. TF-IDF를 측정하다 보면 중요하지 않지만 출현 빈도가 높은 단어들이 여럿 존재한다. 기자라는 직책이나 기자명, 언론사명이 여기에 해당한다. 모든 기사엔 기자라는 직책이 포함돼있거나 언론사 명이 표기된다. 혹은 저작권 표시 문구도 어김없이 등장한다. TF는 높지만 IDF는 1로 수렴되는 단어들이다.
알고리즘 설계자는 분석에 방해가 되는 이런 류의 단어들을 불용어로 처리한다(이성직 & 김한준, 2009). 분석 대상에서 제외한다는 뜻이다. 문제는 불용어를 어떻게 정의하느냐에 따라 중요한 키워드가 빠질 수도 있고 삭제될 수도 있다. 불용어 처리의 기준과 정의를 명확하게 밝히지 않으면 오해를 살 만한 결과값이 도출될 수도 있다.
검색을 포함한 다양한 용도로 확장
TF-IDF 알고리즘이 활용되는 용도는 워낙 다양해서 한정해서 언급하기는 어렵다. 검색엔진은 TF-IDF가 기반 기술로 활용되는 사례에 해당한다. 질의어 기반으로 검색 서비스를 제공한다면 TF-IDF를 일정 수준 활용하지 않을 수 없다.
’블로터‘라는 검색 질의어를 입력하면 검색엔진은 ’블로터‘라는 단어의 TF-IDF 가중치를 계산한 뒤 가중치가 가장 높은 문서를 상위에 노출할 수 있다. 물론 이 과정에는 [bref desc="질의어와 문서의 유사도를 측정하는 수학모델이다. 단어 벡터 모델이라고도 한다."]벡터스페이스모델[/bref]이라는 추가적인 수학 모델도 함께 적용된다.
기계학습 알고리즘을 통해 문서 내 이슈 키워드를 추출해내는 것도 가능하다. 실제 연구도 진행되고 있다. 하지만 이성직·김한준(2009) “기계학습 알고리즘을 이용한 방법은 키워드 추출을 위한 예측 모델을 만들기 위해 고품질의 학습데이터를 준비해야 하는데 이에 대한 비용이 매우 클 뿐 아니라 그것의 정확도가 학습데이터에 의존하므로 수시로 변화하는 뉴스 문서에 이를 적용하는 것은 바람직하지 않다”고 지적했다. 뉴스 문서의 속성 변화가 워낙 역동적이어서 사전 학습이 무력화될 가능성이 높다는 것이다.
TF-IDF는 문서 분류에도 적용이 가능하다. 예를 들어 블로터라는 단어의 TF-IDF 가중치가 특정 값 이상인 문서를 유사 문서로 분류한다고 가정하면 간단한 분류 공식이 성립될 수 있다. 성능은 비교 측정해봐야 하겠지만 어려운 클러스터링 알고리즘을 사용하지 않고서도 간단한 작업을 수행할 수 있는 것이다.
이를 더 확장하면 특정 상품에 대한 평이 과도하게 부정적이거나 긍정적인 문서를 분류해냄으로써 편향된 리뷰를 걸러낼 수 있는 시스템도 만들어낼 수 있다(Yeon, J., et all, 2013). 물론 다른 알고리즘과의 결합, 변형을 통해서 달성할 수 있는 용도다.
결론적으로 TF-IDF는 정확한 뉴스를 검색엔진을 통해 찾고자 하는 독자들에게 가장 만족스런 응답을 제공하는 알고리즘이라 할 수 있다. 이 과정에서 뉴스의 순위를 결정하는데 중추적인 역할을 한다. 특히 뉴스 클러스터 안에서 순위를 결정하는 데에도 이 알고리즘은 활용될 수 있다.
참고 문헌
- 이말례, & 배환국. (2002). TFIDF 를 이용한 키워드 추출 시스템 설계. 인지과학, 13(1), 1-11.
- 이성직, & 김한준. (2009). TF-IDF 의 변형을 이용한 전자뉴스에서의 키워드 추출 기법. 한국전자거래학회지, 14(4), 59-73.
- Luhn, H. P. (1957). A statistical approach to mechanized encoding and searching of literary information. IBM Journal of research and development, 1(4), 309-317.
- Wu, H. C., Luk, R. W. P., Wong, K. F., & Kwok, K. L. (2008). Interpreting tf-idf term weights as making relevance decisions. ACM Transactions on Information Systems (TOIS), 26(3), 13.
- Yeon, J., Shim, J., & goo Lee, S. (2013). Outlier detection techniques for biased opinion discovery. Journal of Society for e-Business Studies, 18(4).
[새소식]
본문 내 "이를 스테밍 작업이라고 한다."는 문구를 삭제했습니다. 스테밍은 불용어 처리와 다르며 동일 의미의 다양한 변형을 하나의 색인어로 바꾸는 작업을 의미합니다. 불용어 처리와는 직접적인 관계가 없습니다. 혼란을 드려 죄송합니다. (2016년 9월28일 오후 3시2분)