초거대 AI(인공지능)는 최근 정보통신기술(ICT) 업계에서 화두로 떠오른 단어다. 기존의 AI보다 고도화된 기능을 갖추고 전문 영역에 활용될 수 있는 AI를 뜻한다. 구글을 비롯한 글로벌 기업과 LG·네이버·KT 등 국내 주요 ICT 기업들도 초거대 AI 개발에 뛰어들었다. 그중 KT는 대학과 연구기관 등이 포함된 'AI 원팀'을 통해 초거대 AI 개발에 힘을 쏟고 있다. AI 원팀의 주요 연구진을 화상으로 만나 AI 원팀만의 차별화 전략에 대해 들었다.

초거대 AI는 기존 AI가 하는 분류뿐만 아니라 생성도 가능하다. 예를 들면 AI가 영화에 대한 긍정적인 평가와 부정적인 평가를 구분하는 것을 분류라고 한다면 이러한 평가들을 요약하거나 챗봇이 이용자의 말을 듣고 다음 문장을 만들어내는 과정이 생성에 해당된다. 서민준 한국과학기술원(카이스트) AI대학원 교수는 "기존 AI가 분류는 잘했지만 생성은 어려웠다"며 "하지만 초거대 AI는 스스로 학습하고 상대적으로 적은 데이터로도 일반화가 가능하다보니 생성하는 것이 더 수월하다"고 말했다.
이러한 경량화와 생성이 가능한 점이 AI 원팀이 내세운 다른 초거대 AI와의 차별점이다. 임준호 한국전자통신연구원(ETRI) 인공지능연구소 언어지능연구실 박사는 "연구를 통해 주어진 맥락을 잘 이해하고 자연스러운 답변을 생성하는 초거대 AI를 구축하는 것이 AI 원팀의 방향성"이라고 말했다.
앞서 초거대 AI 개발을 선언한 LG와 네이버의 경우 AI 원팀의 2000억개보다 더 많은 파라미터(매개변수) 수를 내세웠다. 장 상무는 "데이터 수를 늘리는 것도 중요하지만 데이터를 잘 선별하고 고품질을 만드는 것이 더 중요하다"며 "언어 데이터뿐만 아니라 음성과 영상도 활용해 파라미터를 확대하는 방향으로 논의하고 있다"고 말했다.
초거대 AI는 기존 AI보다 적은 양의 데이터를 필요로 하다보니 기업 입장에서는 보다 다양한 서비스를 더 빠르게 상용화할 수 있다. 생성을 할 수 있다보니 더 자연스러운 대화도 가능하다. 그만큼 소비자들은 AI와 보다 더 원활하게 소통할 수 있고 다양한 서비스를 이용할 수 있는 것이 장점으로 꼽힌다. 적은 양의 데이터로 학습하는만큼 고품질의 데이터가 필요하다. AI 원팀이 데이터를 확보하고 정제하는 작업을 가장 중요하게 여기는 이유다. AI 원팀은 기존에 보유한 한글 데이터와 공공기관들이 공개한 데이터를 적극 활용하고 있다. 인터넷의 각종 웹페이지를 통해 데이터를 모으기도 한다.
초거대 AI는 생활 밀착형 서비스에 이어 제조·금융·물류·유통·의료 등 전문 분야에도 적용될 예정이다. 장 상무는 "기존에는 의료를 비롯한 전문 분야에 AI가 접근하는데 어려움이 있었지만 초거대 AI의 자연스러운 대화를 통해 전문가를 지원하는 것도 가능하게 될 것"이라고 전망했다.
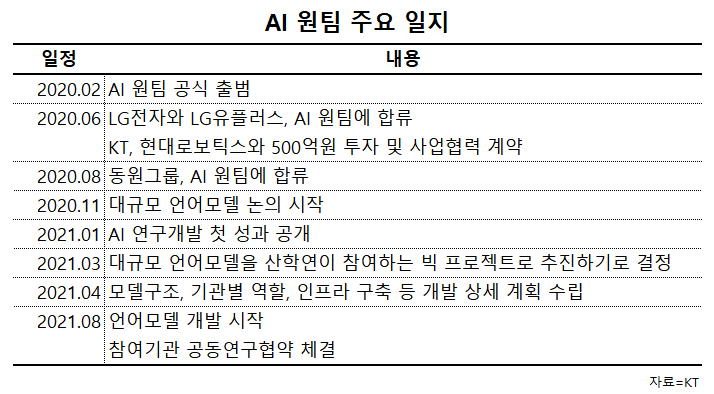
AI 원팀은 지난해 2월 공식 출범했다. KT와 LG유플러스 등 ICT 기업뿐만 아니라 현대중공업그룹·한국투자증권·동원그룹 등 다양한 분야의 기업들이 참여해 AI의 각 산업 적용 노하우를 공유했다. 11월 대규모 언어모델에 대한 논의가 시작됐으며 올해 3월 산학연이 공동 참여하는 프로젝트로 추진하기로 결정됐다. 4월부터는 각 기관의 역할과 상세계획이 수립됐으며 지난 8월 언어모델에 대한 개발이 시작됐다.
초거대 AI 개발은 △대용량 데이터 구축·정제 △한국형 학습 알고리즘 개발 △분산·병렬 알고리즘 개발 △모델 경량화·최적화 △언어모델 응용 애플리케이션 적용 등의 순으로 진행된다. 각 단계에는 KT·한국전자통신연구원(ETRI)·한양대·카이스트·전북대 등이 참여한다.