
회의록 요약과 실시간 변환·번역까지. 네이버의 AI(인공지능) 음성기록 서비스 ‘클로바노트’가 앞으로 추가하려는 기능들이다. 클로바노트는 회의·인터뷰·강의 등 다양한 상황에서 녹음한 대화를 텍스트로 변환해줘 많은 이용자들이 유용하게 쓰고 있는 서비스다. 지난 2020년 11월 서비스를 처음 선보였는데, 1년 만인 지난해 11월 가입자 수 100만명을 돌파하기도 했다. 지난달 24일 네이버 클로바 스피치 팀 한익상 책임리더(이하 한익상)·이찬규 리더(이하 이찬규)를 온라인으로 만나 클로바노트만의 기술 경쟁력, 앞으로의 계획 등에 대해 들어봤다.
Q. 각자 소개부탁드린다.한익상: 삼성전자에 있다 2013년에 네이버에 왔고, 클로바에 온 지 5년 됐다. 20년 넘게 음성인식 엔진 분야만 연구했다. 사실 음성인식 하면 많은 사람들이 안 될 거라고 얘기해왔는데, 클로바노트 서비스가 출시되면서 달라지고 있다. 음성인식을 오래 연구개발했던 사람으로서 굉장히 좋은 시기를 보내고 있다.
이찬규: 네이버에 2006년에 입사해 백엔드 시스템하고 분산 시스템 개발을 하다 네이버랩스에서 개발을 진행했다. 그러다 CPU(중앙처리장치) 장비 없이 딥러닝(컴퓨터가 스스로 외부 데이터를 조합·분석·학습하는 기술)이 가능해지면서 연구실에서도 많이들 딥러닝을 할 수 있게 됐는데, 저도 관련 연구를 하다 음성인식 쪽 딥러닝을 하게 됐고 클로바노트 개발에 참여하게 됐다.
Q. 네이버 클로바노트 서비스 소개 간략하게 해달라.
한익상: 음성 녹음을 음성인식 기능을 활용해 텍스트로 출력하고 원하는 데를 클릭하면 다시 들을 수 있게 하는 기능으로 시작했다. 그러다 화자인식 기능도 내부적으로 갖고 있었기 때문에 화자를 정확히 구분하고 그 다음 음성을 텍스트로 바꿔주는 기능을 추가했다. 사실 이러한 기능을 원하는 이들은 그동안 많았는데, 실제 서비스로 만들기까지가 오래걸렸다.
Q. 오래 걸린 이유가 있을까.
한익상: 딥러닝 기술을 기본적으로 쓰고 있는데, 2년 전부터 ‘빅모델(초대규모 AI·초거대 언어모델이라고도 함)’이라고 표현하는 거대한 모델을 만드는 기법이 개발되기 시작했다. 그래서 기존 음성인식 엔진과 굉장히 큰 격차를 내면서 인식률이 많이 올라가게 됐다. 그 전까지는 단문 발화, 음성 명령 정도만 됐다.
이찬규: 추가 설명하자면 딥러닝 이전에 음성인식에 사용하던 전통적인 모델들이 있었고, 딥러닝이 다양한 분야에 전파되면서 음성인식에도 사용된 거다. 그러면서 음성인식 인식률이 좋아지고 자연스러운 발화들에 대한 음성인식이 가능해졌다. 그 다음 트렌드가 ‘빅모델’ 방식이다. 이게 인식률을 한 단계 더 끌어올리면서 클로바노트 같은 서비스가 가능해진 것이다.
좀 더 말하자면, 기존 딥러닝은 모델을 학습하려면 음성 파일이 있고 그 파일 안에 사람이 뭐라고 말했는지 텍스트도 같이 있어야 했다. 그래서 대량의 음성 데이터가 있어도 그걸 가지고 딥러닝 학습을 바로 할 수가 없었다. 전사 작업(말소리를 음성 문자로 옮겨 적는 작업)이 필요했는데 굉장히 시간과 비용이 많이 들어 학습에 사용할 수 있는 수많은 데이터를 모으는 게 쉽지 않다. 근데 데이터가 많지 않으면 큰 모델을 디자인할 수 없다. 그리고 큰 모델을 만들수록 그걸 학습하기 위해 더 많은 데이터가 필요하다. 두뇌 용량이 커지면 그걸 학습하는 데 또 많은 데이터가 필요해지고, 많은 데이터를 학습하면 더 잘할 수 있는 것과 같은 논리다.
클로바노트에 적용한 빅모델은 모델 자체도 훨씬 더 커졌고, 모델을 학습할 때 텍스트없이 음성 파일만 가지고 있어도 된다. ‘프리 트레인드 모델(PRE-TRAINED MODEL)’이라는 것을 만들 수 있어서다. 빅모델은 내부에 작은 두 개의 모델이 존재한다. 하나가 프리 트레인드 모델, 하나가 ‘파인튜닝(Fine-tuning)’. 파인튜닝은 전사한 스크립트가 더해져 좀 더 잘 튜닝되는 단계다.
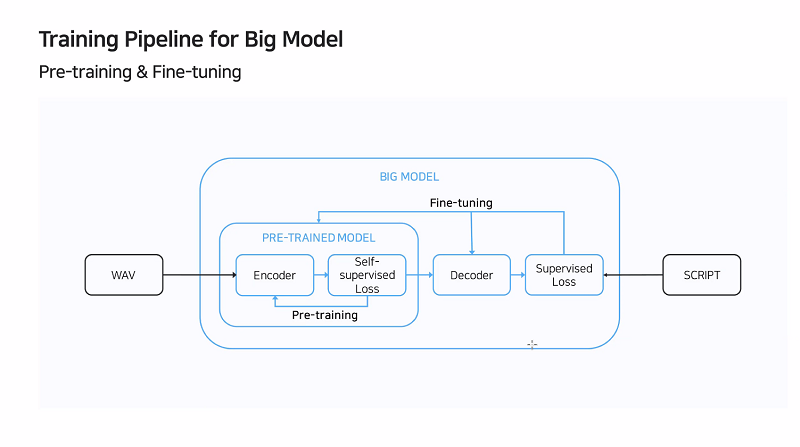
Q. 클로바노트에 적용된 기술에 대해 설명 부탁드린다.
한익상: 크게 두 가지 기술이 있다. 우선적으로 적용된 건 음성인식하고 화자인식. 화자인식은 정확히 누가 무슨 말을 했는지 화자를 구분해 주는 기술이다. 그동안 화자인증이라고 해서 이 말을 한 사람이 당신인지, 나인지 아닌지를 맞춰주는 것에 포커싱 돼 있었다. 예전에 네이버클로바 ‘스피커 프렌즈’라고 AI(인공지능) 스피커 서비스가 있었다. 특히 일본에 출시한 건 음성 메시지를 보낼 때 이게 그 주인이 말한 것인지 반드시 확인해야 하는 조건이 있었다. 그러다보니 사용처가 제한적이었다. 그런데 클로바노트 같은 경우 누구인지 인증하는 것이 아니라 화자별로 구분하는 것이 필요하다보니 관련 기술을 개발해 클로바노트에 처음 적용한 거다. 화자인식 기술 연구자들에게 큰 동기부여가 된 서비스다. 어디에 적용할지 애매했는데 딱 맞는 케이스가 나온 것이다. 물론 음성인식 기술과 함께 빛을 볼 수 있었고.이찬규: 저희가 또 재미있는 기술을 개발했다. 생각보다 두 개 국어로 회의를 하는 사람들이 많았다. 그런데 한국어랑 영어가 혼용되는 경우 현재 어떤 인식기로도 스크립트를 만들 수가 없더라. 그래서 한국어랑 영어를 동시에 인식할 수 있는 모델을 개발해보자 해서 새롭게 개발해 이번에 클로바노트에 추가됐다.
Q. 클로바노트의 인식률이 높은 이유는 무엇인가.
한익상: 음성인식의 경우 크게 두 가지 이유때문이다. 빅모델이라는 기법을 한국에서 제일 처음 적용한 것, 그리고 다른 어떤 기관들에 비해 데이터가 많다는 점. 그동안 네이버 동영상 등 내부 여러 서비스들을 통해 쌓아 둔 데이터들이 꽤 있다. 사실 작년에 국가에서도 굉장히 큰 데이터를 오픈했다. ‘AI허브’라고. 그것도 저희가 사용하고 있다.
화자인식은 팀에 좋은 멤버들이 많이 있는 것도 사실이고, 무엇보다 앞서 말한 것처럼 그간 열심히 개발해도 사용할 데가 없었던 게 문제였는데 클로바노트 서비스를 만나면서 해당 연구원들에게 동기부여가 된 측면이 크다. 연구 페이퍼로만 많이 나와 있다가 서비스화하면서 동력을 확보했기 때문에 화자인식 엔진 성능이 좋아진 것 같다는 생각이 든다.
Q. 현재 또 연구되고 있는 기술이 있는가.
한익상: 하나 말씀 드리자면 화자식별 기술. 화자인식 기술이 종류가 많다. 대표적으로 보면 앞서 말한 화자인증, 그리고 화자구분. 화자식별의 경우 이 말을 진짜 누가 했는지 맞히는 거다. 이것도 기술적으로 개발이 거의 다 끝났다. 하지만 서비스적으로 화자의 레이블(표시 기록)을 붙이는 문제가 있다. 그냥 막 붙이면 안 되고 반드시 허용된 어떤 그룹 내에서만 붙여야 해서다. 왜냐면 내 목소리를 갖다가 임의로 레이블을 붙이면 위험하니까. 그런 부분을 정리하고 있고, 화자식별 기능은 올해 내로 출시되지 않을까 한다.
Q. 문장 정제랑 회의록 요약 기능은 언제 추가되나.
한익상: 하이퍼클로바라는 거대 언어모델을 활용해 요약을 한다거나, 문장을 좀 깔끔하게 정리해준다거나 하는 등의 기술이 가능한 걸 확인했다. 출시를 위해 최종 튜닝 중이다. 물론 출시된다 해도 아직은 이용자 입장에서 부족한 부분이 있을 것 같지만, 또 다른 가능성을 보여줄 수 있다고 생각한다. 문장 정제의 경우 간투사와 같이 쓸데없는 말들을 지워주는 1차적인 정제가 있는데 이 기능이 먼저 출시될 것 같고, 그 다음 이해하기 쉽게 바꿔 말하는 패러프레이징 요약은 시간이 좀 더 필요할 것 같다.
Q. 클로바노트의 정확도를 높이는 데 도움이 되는 팁이 있다면?
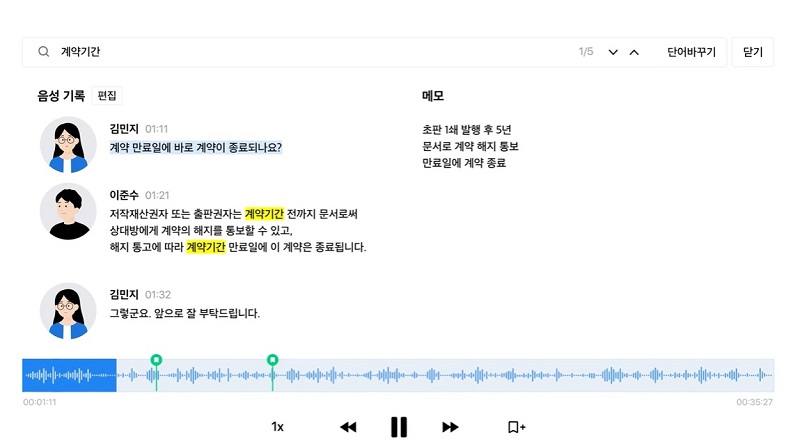
한익상: 먼저 키워드 부스팅 기능. 클로바노트 서비스에 자주 쓰는 단어 등록이 있다. 맥락에 익숙하지 않으면 단어가 헷갈릴 수 있는데, 이 기능을 활용하면 인식률이 굉장히 많이 올라간다. 또 회의 같은 걸 하면서 메모를 할 수 있는 기능이 있는데 거기서 저희가 또 실제 많이 쓰는 말들을 추출하기 때문에 메모 기능만 잘 써도 인식률이 좋아질 거다.
Q. 보안이 걱정된다.
한익상: 두 가지 방식으로 안전하게 처리하고 있다. 암호화와 접근제어. 내부 서버가 되게 많은데, 서버들이 접근할 수 있는 서버가 또 있다. 제한을 해둬서 임의의 경로에서 접근할 수 없도록 해놨다.
Q. 앞으로의 목표 혹은 마지막으로 하고 싶은 말이 있다면.
한익상: 올해 저희 서비스적 목표는 일단 글로벌 출시다. 일본 출시를 지금 준비하고 있고 연내 미국을 시작해 글로벌 출시를 보고 있다. 두 번째 목표는 클로바노트의 방향성이다. 지금 단순히 음성 기록을 텍스트로 바꿔주는 것에 치중돼 있는데, 문장 정제나 회의록 요약 등을 포함해 회의 자체를 분석할 수 있는 것들을 준비 중이다. 그 다음에 예컨대 회의를 할 때 회의를 주관하는 사람이 있다면, AI가 회의 자체를 분석해 그 사람을 도와줄 수 있는 것들도 보고 있다. ‘워크스페이스(업무공간)의 AI’를 꿈꾼다고 보면 될 것 같다. 회의할 때 메모를 하느라 집중 못하는 사람들도 있는데, 회의 자체에 좀 더 집중할 수 있게 최대한 도와드리고 훨씬 더 생산적인 업무들을 할 수 있게 하고 싶다.
이찬규: 클로바노트가 잘 하는 이유를 생각해보면 데이터도 중요하지만 확실히 사람인 것 같다. 좋은 사람들이 있어서. 그리고 그런 사람들이 모여서 서비스와 연구의 중심을 잘 잡는 것. 이게 굉장히 중요한 게 연구에만 너무 중심이 가 있으면 서비스적으로 적용할 수 없거나 비현실적이거나 이상적 방향으로 흘러가는 경우가 있다. 자기는 계속 뭔가 하는 것 같은데 가시적 결과가 나오지 않기도 하고. 또 서비스에 너무 집중하면 길게 혹은 멀리 보지 못하고 단편적 문제들만 해결해 나가게 되는데, 연구자 입장에서 이건 동기부여가 안 된다. 균형이 굉장히 중요한데 연구적으로도 서비스적으로도 중심을 잘 잡아서 진행하다보니 연구하는 분들이 성취감도 느끼고 연구적 성과도 내고, 서비스적으로 좋은 결과를 만들어낼 수 있지 않았나 싶다. 그리고 단기적으로 재밌는 과제들을 많이 하고 있고 내부적으로 더 좋은 성능의 모델들을 이미 개발했다. 서비스에 적용하는 과정은 또 여러 단계가 있어 시간이 좀 걸리겠지만. 가까운 시일엔 실시간 스트리밍으로 인식 결과를 받아볼 수 있을 것 같다. 빠르면 올해 상반기쯤 적용될 거다. 추가로 파파고 팀하고 협력해 번역까지 바로 할 수 있는 기능도 준비 중이다.