마케터에게 데이터란 자신의 마케팅 성과를 수치로 보는 일과 같습니다. 광고 집행 이후 노출과 클릭, 전환 같은 사람들의 반응을 수치로 확인합니다. 단순히 데이터를 확인하는 데서 나아가 분석을 통해 인사이트를 도출해 냅니다. 이는 다음 전략을 수립하기 위한 근거가 돼 줍니다.
지난 ‘마케팅 분석 실전편 : 통계 활용하기 ①’에서는 마케터가 데이터에서 의미를 찾기 위한 방법으로서 기본적인 통계 분석에 대해서 알아보았습니다. 표준편차와 표준점수를 활용해 데이터를 정확히 파악하고, A/B 테스트를 통해 가설 검정하는 방법에 대해 이야기했습니다. 이번에는 지난 시간에 이어 마케팅 데이터가 갖고 있는 패턴을 파악할 수 있는 데이터의 상관관계와 예측 분석에 대해 이야기해보고자 합니다.
. . . . .
스텝 3. 매출에 영향을 주는 데이터는 무엇일까?
데이터 간의 관련성이 궁금하다면, 상관분석을 주목!
전환수나 매출이 어떤 광고 데이터와 관련이 있는지 궁금한 분이 계신가요? 그렇다면 상관분석을 주목해 주세요.
상관분석이란, 데이터의 관련성을 찾아내는 통계 분석 방법을 의미합니다. 상관분석은 지표간의 관련성 수준을 수치적으로 알려주는 통계적 분석 방법입니다. 특정 변수 X와 Y가 함께 변하는 정도를, 'X와 Y가 각각 변하는 정도'를 나누어 표현합니다. 이때 사용되는 계수를 피어슨 상관계수라고 합니다. 피어슨 상관계수의 경우 변수 X와 Y가 완전히 동일하면 +1, 전혀 다르면 0, 반대방향으로 동일한 경우 -1의 값을 보입니다.

우선 두 변수의 밀접도가 얼마나 강력한가의 기준은 상관계수의 크기(절댓값)로 판단됩니다. 상관계수의 크기가 0에 가까울수록 관련성이 낮고, 1에 가까울수록 관련성이 높다고 볼 수 있어요.
상관도의 정도를 세분화한 기준도 있습니다. 예를 들어 0에서 0.1은 관련성이 거의 없습니다. 0.1부터 0.3의 상관계수는 약한 관련성이 있고, 0.3부터 0.7까지는 어느 정도 관련성이 있다고 판단할 수 있습니다. 만일 상관계수가 정도가 0.7부터 1 사이라면, 관련성이 강하다고 볼 수 있습니다.
한편, 양수와 음수는 비례와 반비례를 나타냅니다. 만일 변수 X와 Y의 상관계수가 0 이상이라면 양의 상관관계를 보입니다. 즉, X가 증가한다면 Y도 증가합니다. 반면 X와 Y의 상관계수가 0보다 작다면 반비례의 관계를 보이게 됩니다. X가 증가하면, Y는 감소합니다.
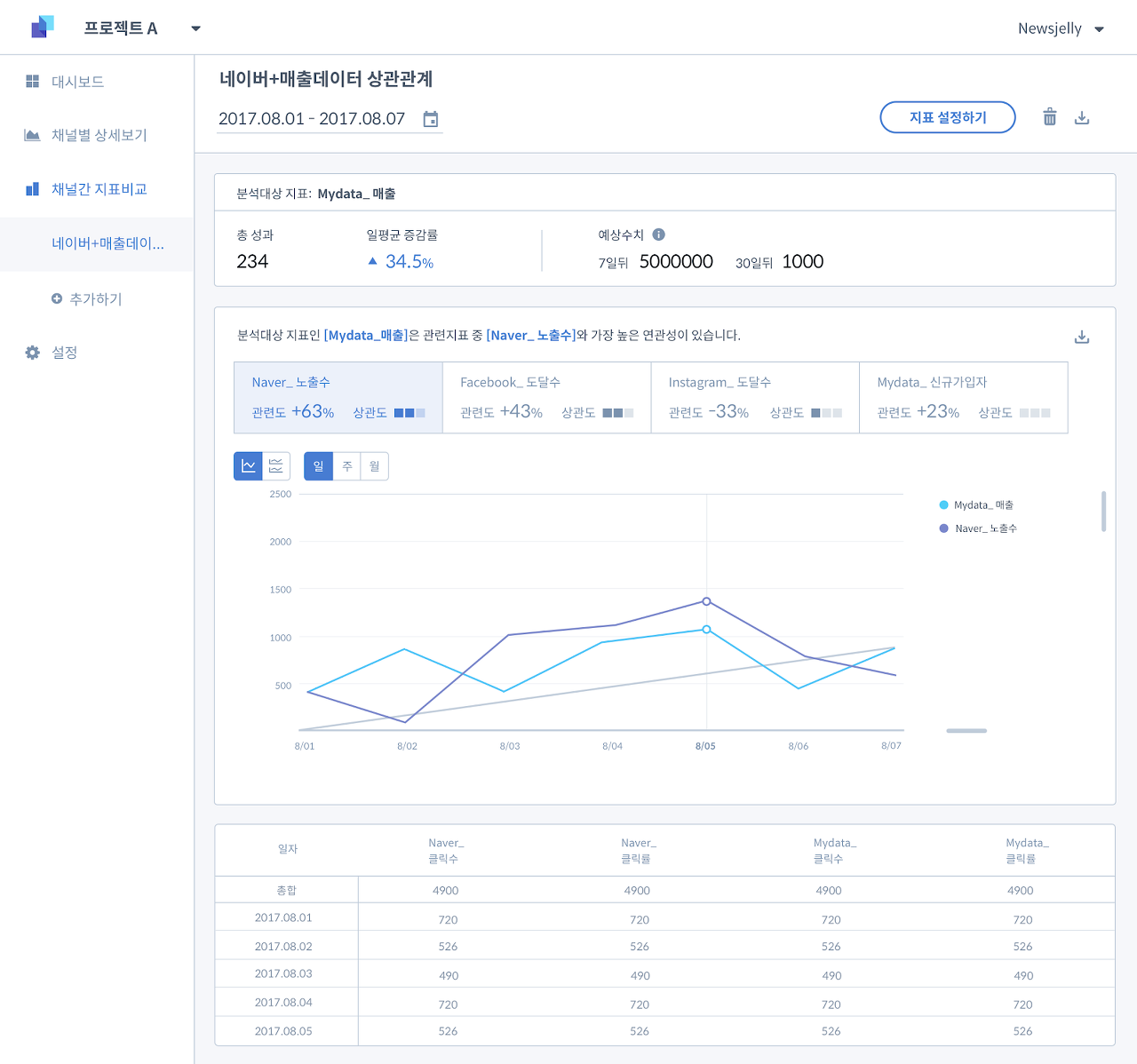
예를 들어 화면에서 매출과 각 광고 데이터 간의 네이버의 경우 63%(피어슨 상관계수는 0.63), 인스타그램 도달수는 -33%(-0.33)입니다. 이를 다시 해석하자면, 매출은 네이버의 노출수와 강한 양의 상관관계, 인스타그램의 도달수는 약한 음의 상관관계가 있습니다. 즉, 네이버의 노출수는 인스타그램의 도달보다 연관관계가 강합니다. 매출 상승과 긍정적인 관계가 있다고 해석할 수 있습니다.
다만 상관도가 높다고 해서 어느 두 데이터 사이의 인과관계가 있다고 해석하지 않도록 주의해주세요. 상관분석은 상관관계와 인과관계는 다른 것이고, 인과관계가 궁금하다면 회귀분석을 사용하게 됩니다.
스텝4. 클릭수가 내일 어떻게 바뀔지 궁금하다면?
예측 모델로 알아보기
오늘 좋았던 클릭수가 내일도 좋을 수 있을까요? 미래의 성과를 우리는 어떻게 예측할 수 있을까요?
가장 단순하게는 과거의 데이터를 기반으로 판단하는 방법인 시계열 분석이 있습니다. 시계열 분석이란, 과거 데이터의 패턴을 바탕으로 미래의 데이터를 예측하는 것입니다.
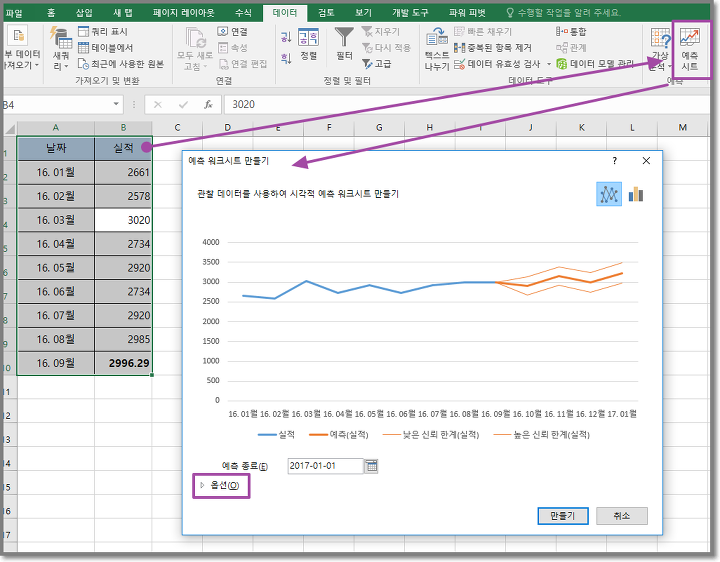
예컨대 이미지의 '실적'을 디지털 마케팅에 대입해본다면, 1월부터 9월까지의 실적(하늘색 실선)을 바탕으로 10월 이후의 실적(주황색 실선)을 예측하는 것입니다. 주황색 실선 주변에 있는 다른 실선들은 실적의 오차 범위를 의미합니다.
이 데이터는 또한 시계열 분석을 이용한 결과랍니다. 또한 이 데이터의 정확도를 개선하기 위해 예를 들어 최신 데이터일수록 그 데이터에 가중치를 부여하여 계산하는 지수 평활법을 활용할 수 있습니다.
여기까지 읽은 분들은 이렇게 반문하고 싶을 겁니다. “하지만 마케팅의 경우 외부 요인도 많은걸요? 이런 값을 얼마나 신뢰할 수 있죠?”
비단 마케팅뿐만 아니라 이런 다양한 변인을 갖고 있는 상황의 예측 모델을 개선하기 위해 다양한 방법이 있습니다. 그중 다른 외부 요인의 영향까지 평가할 수 있는 causal impact라는 방법을 소개하겠습니다.
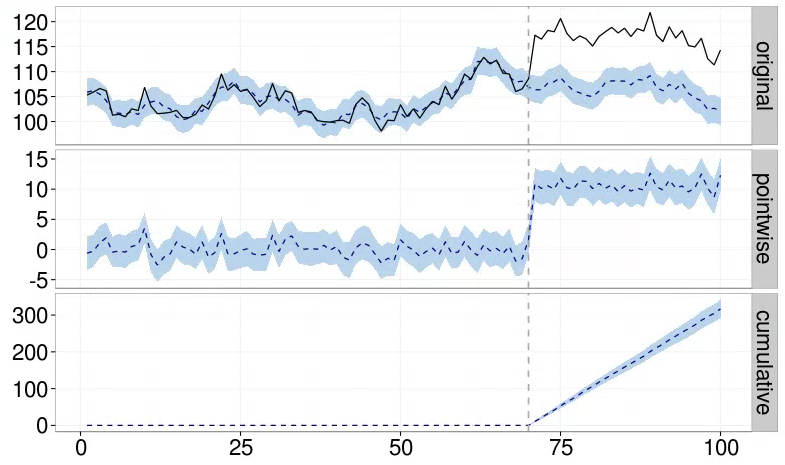
causal impact는 구글에서 공개한 예측 분석 모델 패키지로, 특정 사건이 미친 영향과 장기적인 데이터의 변화를 분석하는 데이터입니다. 장기적인 데이터 변화의 예시는 계절 효과(주기적인 상승 및 하락), 혹은 장기적인 변화를 생각할 수 있습니다. 반명, 특정 사건이 미친 영향은 마케팅 집행 결과를 의미합니다.
고급 아이스크림 전문점 마케팅을 예시로 생각해 봅시다. 월말 보고서를 작성하기 위해 데이터 분석을 한 결과, 다음 특징을 확인했습니다.
- 계절 효과 - 식음료 광고에는 계절 효과가 있다. 여름에 매출이 높고, 겨울에는 매출이 상대적으로 낮다.
- 장기적인 변화 - 지난 3년간 소득이 증가하면서 전반적으로 매출이 상승하고 있다.
- 특정 사건 - 최근 2주간 유튜브에 동영상 광고를 집행한 이후 매출이 올랐다.
causal impact는 3)의 마케팅 효과를 판단할 때 1, 2의 영향이 있는지를 함께 판단해줄 수 있습니다. 현재 구글에서 공개한 causal impact를 사용할 수 있는 프로그램은 R로 구성되어 있습니다.
. . . . .
합계와 평균 그 이상의 분석을 꿈꾸신다면…
멀게만 느껴졌던 통계, 사실은 마케터 여러분들이 궁금한 다양한 문제에 대한 해답이 필요할 때 활용할 수 있습니다. 엑셀 외의 다양한 프로그램에서도 이러한 데이터 분석이 가능합니다. 오늘 한 번, 합계와 평균 그 이상의 데이터 분석을 진행해 보시면 어떨까요?
* 이 글은 퍼포먼스 마케팅을 위한 다채널 광고 분석 솔루션 매직테이블 브런치에도 게재됐습니다. 매직테이블 브런치에서 더 많은 마케팅 인사이트를 확인하세요!